Balans.bg surpasses 15K users on legal-tech platform with a knowledge base spanning 25 years
Kreston BulMar is the most prominent Bulgarian accounting and consulting agency, which, over the last 25+ years, has authored thousands of articles, analyses, commentaries, videos, handbooks, and a dozen textbooks. By 2019 they came to the idea of establishing a long-term partnership with an IT company to help them create a custom knowledge management platform to organize and monetize their professional expertise.
Services
Planning & Requirements
Development & Testing
Deployment & Support
Challenge
2019 was the year Kreston BulMar - the most prominent Bulgarian accounting and consulting agency in the last 25+ years, went to create a unique platform for further sharing its vast knowledge. The critical part was managing the thousands of documents accumulated over the last three decades. Lexis Solutions rose to the challenge. An abundant administration with sophisticated document parsing algorithms and a responsive, SEO-optimized client application was created, offered, and successfully implemented.

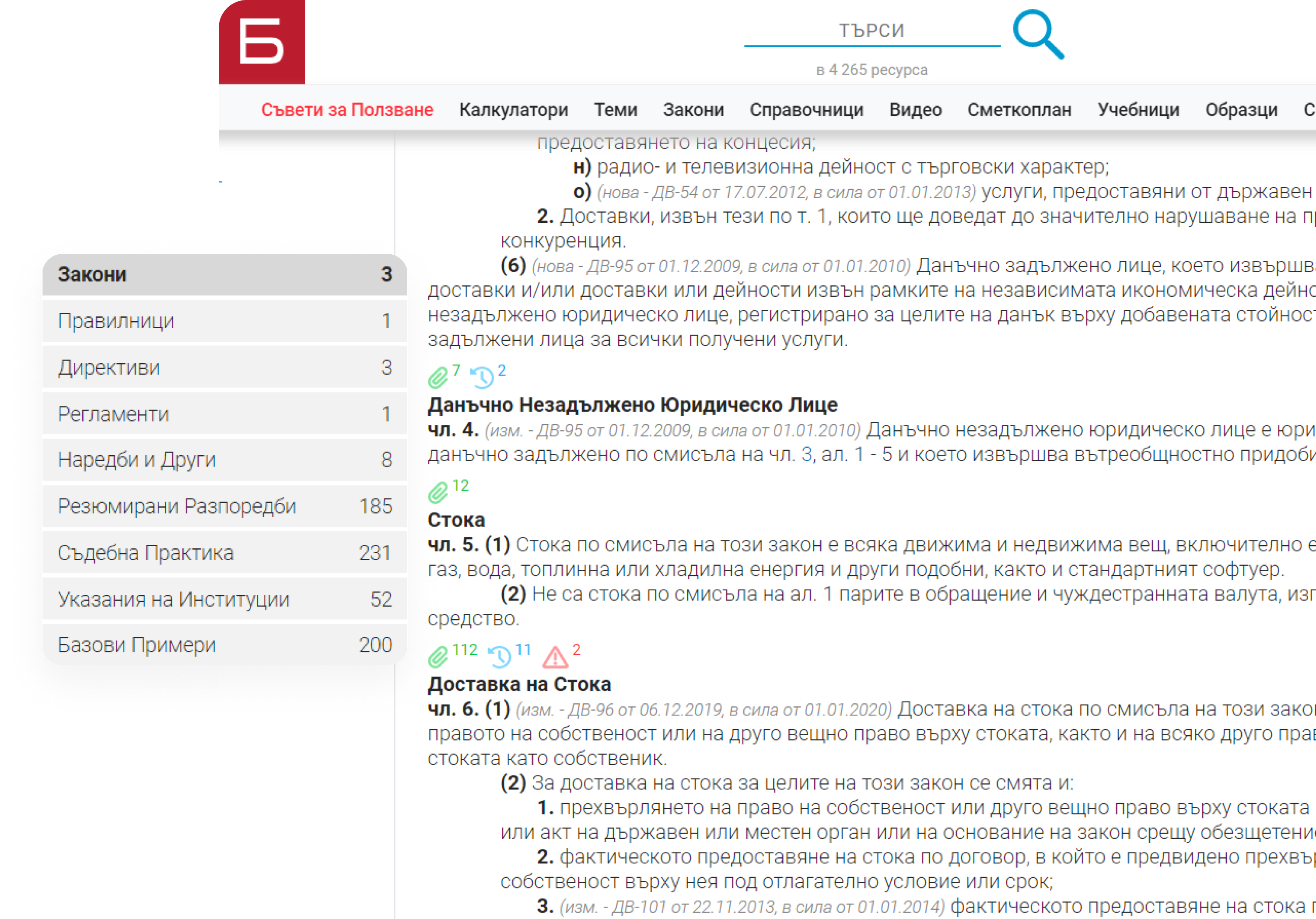
Solution
Balans.bg has nearly 4 000 unique resources separated into 13 categories - calculators, articles, legal acts, videos, news, textbooks, etc. With such a rich database, the platform offers its users a solution for every business case.

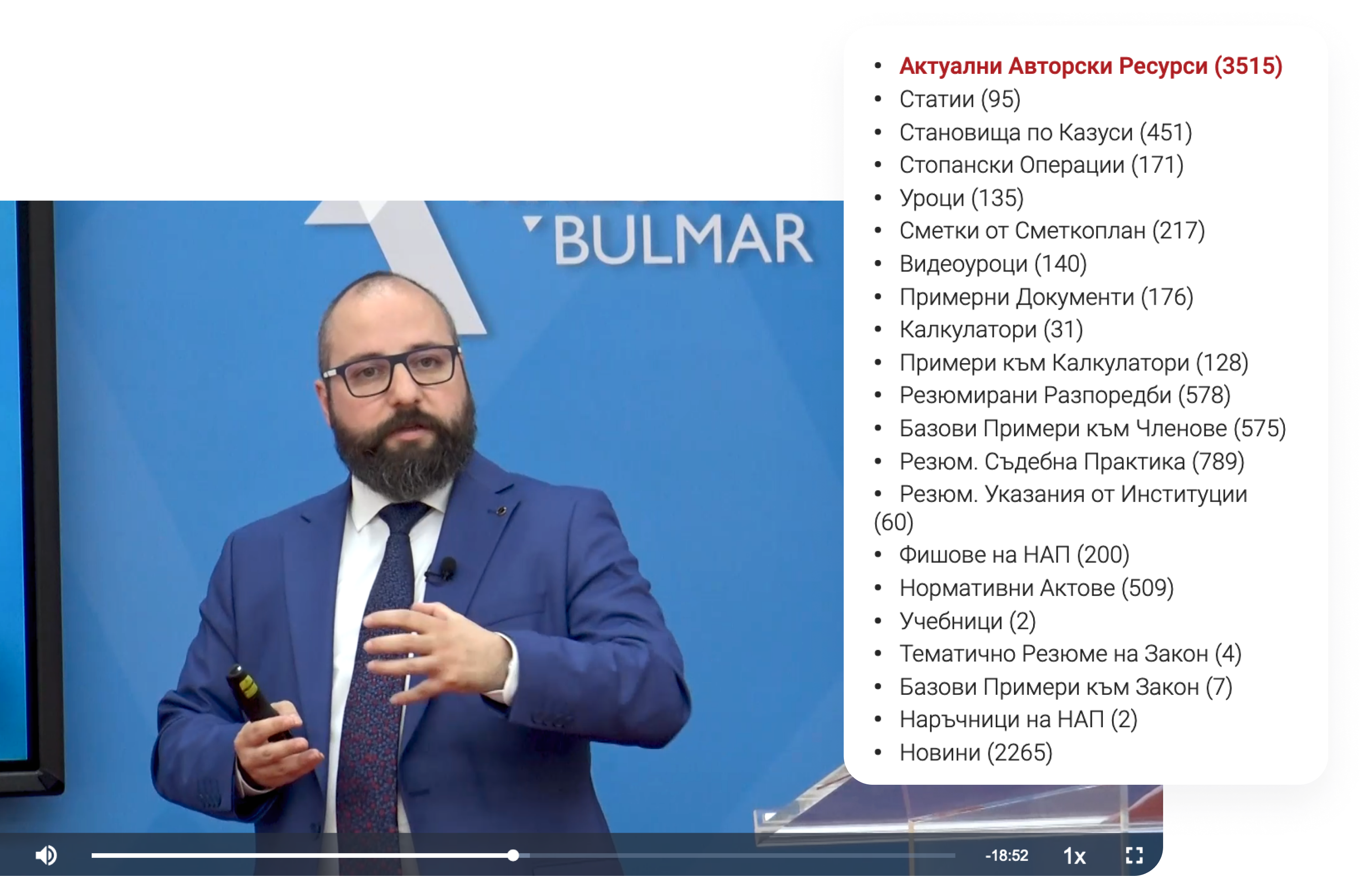
Resources are interconnected
Each resource has connections to other resources, and their sum accounts for well over 10 000 links. By visualizing and organizing linked resources, users can seamlessly acquire a complete understanding of the issue and hand and solve their professional case.


Constant updates
Balans.bg detects whenever law articles are updated and notifies admins of potentially outdated resources. The process has been guaranteed by the links between resources and legal acts and guarantees.

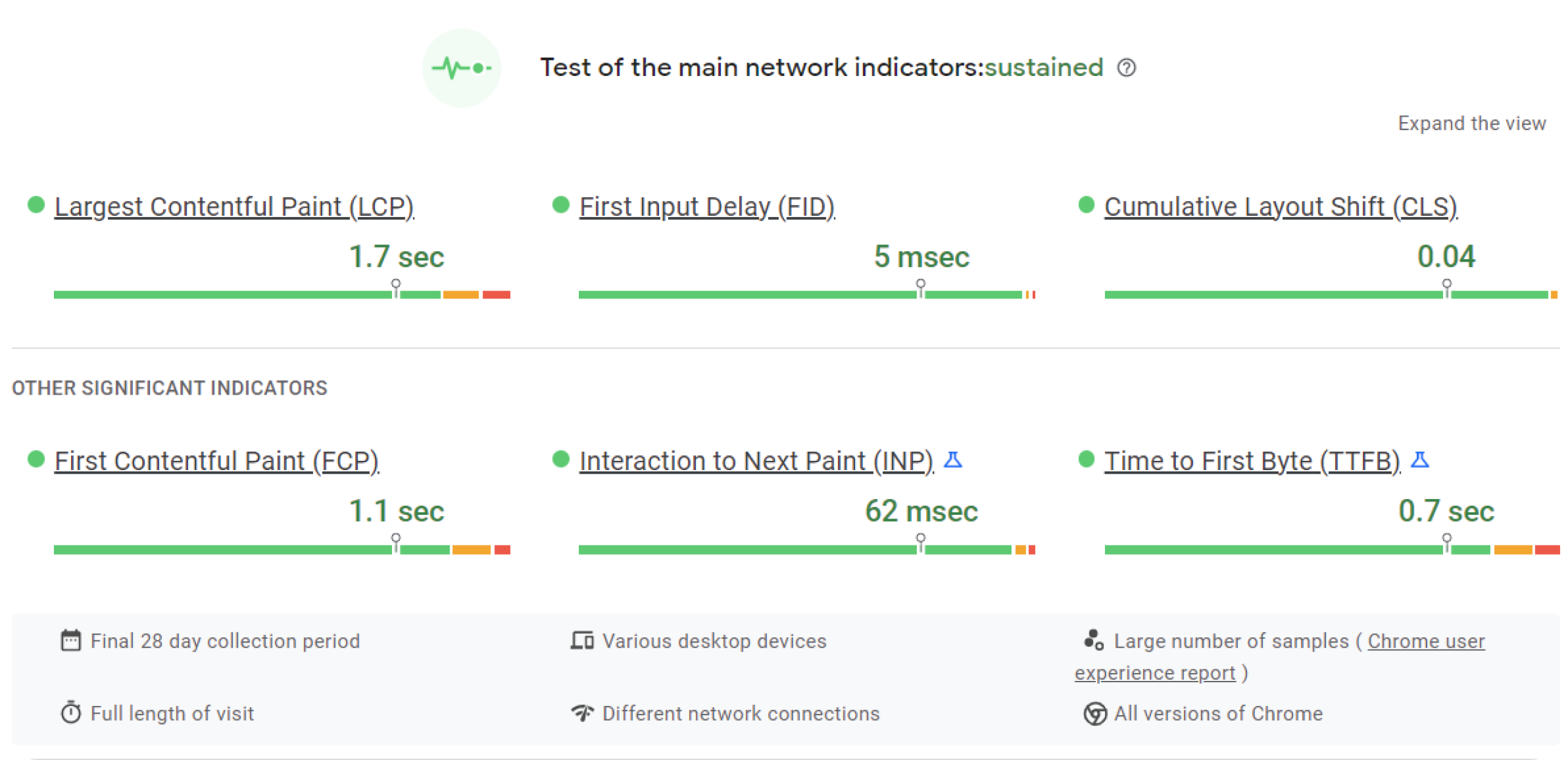
Performance as fast as the speed of light
Because of the fantastic architecture, feature planning, and caching for quick access, each user can find their needed solutions as fast as the speed of light.
Results
15K+
registered users
24K+
connected resources
120%
increase in revenue YoY
Lexis Solutions completed a project that we thought improbable to successfully implement. Rather than focusing on the problems they thought of solutions and made it happen.

